최근 ShortCha 광고가 많이 보이길래 들어가 보았습니다.
1분 내외의 짧은 영상이 30~60편 정도 올라와 있더라고요. 짧게 시간 날 때 보기 딱 좋은 구성인데, 구독료가 엄청나더군요.
구독 가격을 보니, 한 주에 2만원…..
다른 OTT 서비스는 이미 월 1~2만원으로 구독하고 있어서, 이 가격까지 추가로 부담하긴 어렵더라구요. 그래서 어쩔 수 없이 광고 보고 무료로 사용하는 쪽을 선택했습니다.
ShortCha는 ‘젤리’라는 포인트로 에피소드를 볼 수 있는데, 광고를 보면 젤리를 모을 수 있어요. 그런데 여기서 문제가 있었습니다. 1분짜리 짧은 에피소드를 보려면 3~4분짜리 광고를 봐야 하는 거죠. (짧은 광고도 있지만, 계속 광고를 보다 보면 긴 광고가 보이는 시스템인것 같습니다. ) 이건 ROI(Return On Investment)가..
그래서 . “자동화 봇을 만들어볼까?”
처음에는 광고의 X버튼을 직접 클릭하려고 했어요. element로 되어 있으면 xpath로 찾을 수 있지만, 영상에 임베디드된 경우도 있더라고요. 그래서 다른 방법을 찾아야 했습니다. 화면을 캡처해서 X버튼을 찾는 방식을 고민하게 되었죠.
“누군가 이미 이런 AI 모델을 만들었을 텐데?” 하고 찾아봤지만, 아쉽게도 찾을 수 없었습니다. 그래서 직접 YOLO를 이용해서 구현하기로 했어요. 처음에는 class 분류 모델을 사용했는데, 닫기 버튼의 위치가 계속 변경되었습니다. 그래서 최종적으로 detection 모델로 변경했습니다.
MODEL_PATH = "best.pt"
model = YOLO(MODEL_PATH)
def yolo_classify(crop_img: Image.Image, side_offset: int) -> Optional[Tuple[str, float, Tuple[int, int, int, int], int]]:
"""Run YOLO on a PIL crop; return a list of (cls_name, conf, (x1,y1,x2,y2), side_offset) for all detections."""
results = model.predict(source=crop_img, conf=PRED_CONF, save=False, verbose=False)
detections = []
for r in results:
for box in r.boxes:
cls_id = int(box.cls[0])
conf = float(box.conf[0])
x1, y1, x2, y2 = [int(v) for v in box.xyxy[0].tolist()]
detections.append((model.names[cls_id], conf, (x1, y1, x2, y2), side_offset))
return detections if detections else None
def _crop_square(img: Image.Image, where: str, ratio: float) -> Tuple[Image.Image, int, int]:
"""Return (crop, x_offset, y_offset) for 'rt' or 'lt' square crops."""
w, h = img.size
side = int(min(w, h) * ratio)
if where == "rt":
crop = img.crop((w - side, 0, w, side))
return crop, w - side, 0
elif where == "lt":
crop = img.crop((0, 0, side, side))
return crop, 0, 0
else:
raise ValueError("where must be 'rt' or 'lt'")
def detect_and_click_corner(d: u2.Device, where: str = "rt") -> Optional[Tuple[int, int, float]]:
"""
Crop corner square (right-top or left-top), run YOLO, map to screen coords, click center.
Returns (cx, cy, conf) or None if no detection.
"""
img = d.screenshot(format="pillow")
crop, x_off, y_off = _crop_square(img, where, SCREEN_CROP_RATIO)
results = yolo_classify(crop, x_off)
if not results:
return None
for class_name, conf, (x1, y1, x2, y2), x_offset in results:
if class_name in ("xbutton", "arrow"):
cx = int((x1 + x2) // 2) + x_offset
cy = int((y1 + y2) // 2) + y_off
d.click(cx, cy)
return (class_name, cx, cy, conf)
return None화면 캡쳐 및 YOLO 모델 (best.pt는 YOLO weight 파일입니다)
이렇게 해서 매일 자동으로 젤리를 모으고, 보고 있는 시리즈는 미리 광고를 다 처리해두면 나중에 광고 없이 한번에 몰아볼 수 있게 했어요.
하지만 YOLO 모델이 항상 완벽한 건 아니었어요. 가끔 닫기 버튼을 찾지 못하는 경우가 있었습니다. 이럴 때를 대비해 fallback 전략을 추가했습니다. YOLO가 실패하면 LLM에게 화면 이미지를 보내서 버튼의 좌표를 불러오는 방식이죠. 이때 캡쳐한 이미지는 나중에 학습 데이터로 활용했습니다.
LLM Query 및 응답 – 예시
응답:
{
"x": 1040,
"y": 54,
"reason": "There is an advertisement overlay on the screen. The 'X' close button is clearly visible at the top-right corner. Clicking at (1040, 54) will close the ad and allow the user to return to the app content."
}
코드
def ask_and_click_by_llm(d, api_url="http://192.168.10.100:4000/v1/chat/completions", api_key="sk-"):
"""
1. Capture the current screen as an image and get current XML.
2. Send the screenshot and XML to the LLM endpoint (chat completion).
3. Receive the recommended click coordinates and reason.
4. Click the received coordinates.
5. Save the image, coordinates, and reason to files.
"""
import datetime
import json
import os
time.sleep(3)
# 1. Capture screenshot
img = d.screenshot(format="pillow")
img_bytes = io.BytesIO()
img.save(img_bytes, format="PNG")
img_bytes.seek(0)
img_b64 = base64.b64encode(img_bytes.read()).decode("utf-8")
# 2. Get current XML dump as string
xml_str = d.dump_hierarchy(compressed=True)
# 3. Prepare OpenAI/LiteLLM chat completion payload
payload = {
"model": "azure/gpt-4.1",
"messages": [
{
"role": "system",
"content": (
"You are a UI automation assistant. "
"Given a screenshot and XML, suggest the best click position and explain why. "
"If the screen contains an advertisement overlay, prioritize clicking a '>>' or 'X' button to skip/close it. "
"Respond in JSON: {\"x\": int, \"y\": int, \"reason\": str}"
)
},
{
"role": "user",
"content": [
{"type": "text", "text": "Here is the current screen and its XML. Where should I click and why?"},
{"type": "image_url", "image_url": f"data:image/png;base64,{img_b64}"},
{"type": "text", "text": xml_str}
]
}
]
}
headers = {}
if api_key:
headers["Authorization"] = f"Bearer {api_key}"
try:
resp = requests.post(api_url, json=payload, headers=headers, timeout=60)
resp.raise_for_status()
# Try to extract JSON from LLM response
content = resp.json()["choices"][0]["message"]["content"]
# If LLM returns code block, extract JSON part
if "```json" in content:
content = content.split("```json")[1].split("```")[0].strip()
result = json.loads(content)
x, y = result.get("x"), result.get("y")
reason = result.get("reason", "")
print(f"LLM response: click at ({x},{y}), reason: {reason}")
# 5. Save image, coordinates, and reason to files
now = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
save_dir = "llm_click_log"
os.makedirs(save_dir, exist_ok=True)
img_path = os.path.join(save_dir, f"screen_{now}.png")
info_path = os.path.join(save_dir, f"info_{now}.json")
xml_path = os.path.join(save_dir, f"xml_{now}.xml")
img.save(img_path)
with open(info_path, "w", encoding="utf-8") as f:
json.dump({"x": x, "y": y, "reason": reason}, f, ensure_ascii=False, indent=2)
with open(xml_path, "w", encoding="utf-8") as f:
f.write(xml_str)
print(f"Saved screenshot to {img_path}")
print(f"Saved click info to {info_path}")
if x is not None and y is not None:
d.click(int(x), int(y))
print(f"Clicked at: ({x},{y})")
return (x, y, reason)
else:
print("No coordinates received from LLM.")
return None
except Exception as e:
print(f"LLM API request failed: {e}")
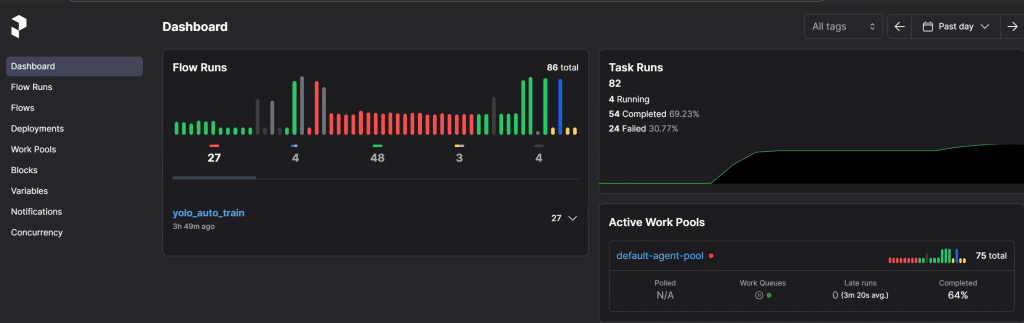
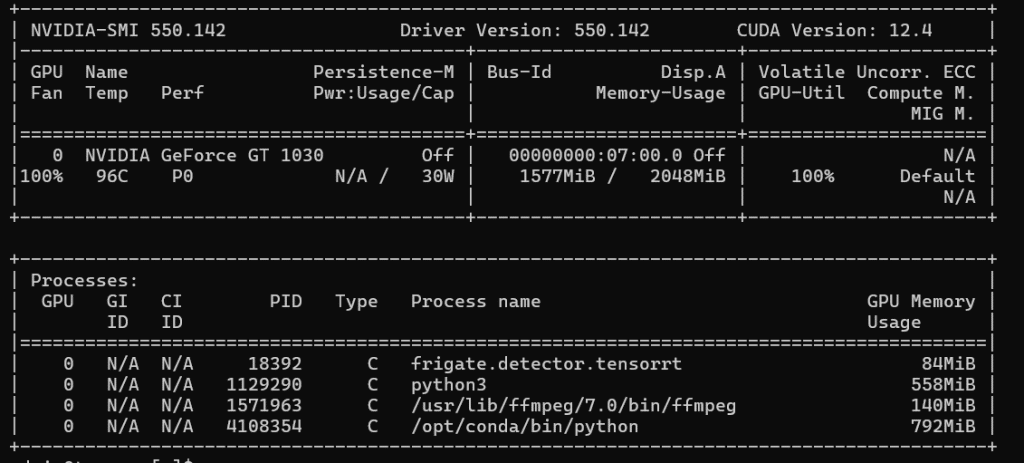
return None이 과정을 좀 더 체계적으로 관리하고 싶었어요. 그래서 Prefect를 설치해서 CI/CD 파이프라인을 구축했습니다. 단순한 이미지 학습인데도 CPU로는 60분이나 걸리더라고요. 그래서 NAS의 GPU를 활용하기로 했습니다. 고성능은 아니지만… 없는 것보다는 훨씬 나으니까요.
위 코드를 보면 알겠지만, 코드는 대부분 CoPilot 으로 작성했습니다. 실제로 직접 코딩하는 시간보다 모델을 학습 시키는 시간이 월씬 많이 걸렸죠.
봇과 MLOps의 전체 프로세스를 정리하면 다음과 같습니다:
- ShortCha에서 광고 보고 젤리 획득하기
- 보던 시리즈의 새 에피소드 미리 확보하기 (광고 보면서)
- YOLO 모델로 화면 캡처 후 닫기 버튼 탐지 및 자동 클릭
- YOLO가 버튼을 찾지 못하면 LLM에게 화면 이미지를 보내 좌표 확보
- LLM이 처리한 이미지와 데이터를 저장 (학습 데이터로 활용)
- 확보한 좌표를 클릭하여 미션 완료
- 저장된 이미지 확인 후 학습 데이터 보정 (여기는 사람이…)
- Prefect로 모델 학습 후 YOLO 모델 업데이트
이렇게 해서 YOLO와 LLM을 조합한 자동화 시스템을 만들었고, Prefect로 MLOps 파이프라인까지 구축하니 그럴듯하게 돌아가더라고요. 실패하면 LLM이 보완하고, 그 데이터로 다시 학습하는 구조입니다.
Prefect Dashboard
열심히 돌고 있는 NAS – GPU
CPU로 돌릴 때. ㅠㅠ

“ShortCha 광고 자동화 봇 만들기: YOLO와 LLM으로..”에 한개의 의견